Autobatching for Bayesian inference#
![]()

This notebook demonstrates a simple Bayesian inference example where autobatching makes user code easier to write, easier to read, and less likely to include bugs.
Inspired by a notebook by @davmre.
import matplotlib.pyplot as plt
import jax
import jax.numpy as jnp
import jax.scipy as jsp
from jax import random
import numpy as np
import scipy as sp
Generate a fake binary classification dataset#
np.random.seed(10009)
num_features = 10
num_points = 100
true_beta = np.random.randn(num_features).astype(jnp.float32)
all_x = np.random.randn(num_points, num_features).astype(jnp.float32)
y = (np.random.rand(num_points) < sp.special.expit(all_x.dot(true_beta))).astype(jnp.int32)
y
array([0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0,
1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,
1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0,
0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1,
1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0], dtype=int32)
Write the log-joint function for the model#
We’ll write a non-batched version, a manually batched version, and an autobatched version.
Non-batched#
def log_joint(beta):
result = 0.
# Note that no `axis` parameter is provided to `jnp.sum`.
result = result + jnp.sum(jsp.stats.norm.logpdf(beta, loc=0., scale=1.))
result = result + jnp.sum(-jnp.log(1 + jnp.exp(-(2*y-1) * jnp.dot(all_x, beta))))
return result
log_joint(np.random.randn(num_features))
Array(-213.23558, dtype=float32)
# This doesn't work, because we didn't write `log_prob()` to handle batching.
try:
batch_size = 10
batched_test_beta = np.random.randn(batch_size, num_features)
log_joint(np.random.randn(batch_size, num_features))
except ValueError as e:
print("Caught expected exception " + str(e))
Caught expected exception Incompatible shapes for broadcasting: shapes=[(100,), (100, 10)]
Manually batched#
def batched_log_joint(beta):
result = 0.
# Here (and below) `sum` needs an `axis` parameter. At best, forgetting to set axis
# or setting it incorrectly yields an error; at worst, it silently changes the
# semantics of the model.
result = result + jnp.sum(jsp.stats.norm.logpdf(beta, loc=0., scale=1.),
axis=-1)
# Note the multiple transposes. Getting this right is not rocket science,
# but it's also not totally mindless. (I didn't get it right on the first
# try.)
result = result + jnp.sum(-jnp.log(1 + jnp.exp(-(2*y-1) * jnp.dot(all_x, beta.T).T)),
axis=-1)
return result
batch_size = 10
batched_test_beta = np.random.randn(batch_size, num_features)
batched_log_joint(batched_test_beta)
Array([-147.84032, -207.02205, -109.26076, -243.80833, -163.02908,
-143.84848, -160.28772, -113.7717 , -126.60544, -190.81989], dtype=float32)
Autobatched with vmap#
It just works.
vmap_batched_log_joint = jax.vmap(log_joint)
vmap_batched_log_joint(batched_test_beta)
Array([-147.84032, -207.02205, -109.26076, -243.80833, -163.02908,
-143.84848, -160.28772, -113.7717 , -126.60544, -190.81989], dtype=float32)
Self-contained variational inference example#
A little code is copied from above.
Set up the (batched) log-joint function#
@jax.jit
def log_joint(beta):
result = 0.
# Note that no `axis` parameter is provided to `jnp.sum`.
result = result + jnp.sum(jsp.stats.norm.logpdf(beta, loc=0., scale=10.))
result = result + jnp.sum(-jnp.log(1 + jnp.exp(-(2*y-1) * jnp.dot(all_x, beta))))
return result
batched_log_joint = jax.jit(jax.vmap(log_joint))
Define the ELBO and its gradient#
def elbo(beta_loc, beta_log_scale, epsilon):
beta_sample = beta_loc + jnp.exp(beta_log_scale) * epsilon
return jnp.mean(batched_log_joint(beta_sample), 0) + jnp.sum(beta_log_scale - 0.5 * np.log(2*np.pi))
elbo = jax.jit(elbo)
elbo_val_and_grad = jax.jit(jax.value_and_grad(elbo, argnums=(0, 1)))
Optimize the ELBO using SGD#
def normal_sample(key, shape):
"""Convenience function for quasi-stateful RNG."""
new_key, sub_key = random.split(key)
return new_key, random.normal(sub_key, shape)
normal_sample = jax.jit(normal_sample, static_argnums=(1,))
key = random.key(10003)
beta_loc = jnp.zeros(num_features, jnp.float32)
beta_log_scale = jnp.zeros(num_features, jnp.float32)
step_size = 0.01
batch_size = 128
epsilon_shape = (batch_size, num_features)
for i in range(1000):
key, epsilon = normal_sample(key, epsilon_shape)
elbo_val, (beta_loc_grad, beta_log_scale_grad) = elbo_val_and_grad(
beta_loc, beta_log_scale, epsilon)
beta_loc += step_size * beta_loc_grad
beta_log_scale += step_size * beta_log_scale_grad
if i % 10 == 0:
print('{}\t{}'.format(i, elbo_val))
0 -175.56161499023438
10 -112.76364135742188
20 -102.41358184814453
30 -100.27793884277344
40 -99.55818176269531
50 -98.18000793457031
60 -98.60237121582031
70 -97.6973648071289
80 -97.53225708007812
90 -97.17939758300781
100 -97.09412384033203
110 -97.40316772460938
120 -97.04466247558594
130 -97.2058334350586
140 -96.89036560058594
150 -96.91874694824219
160 -97.00558471679688
170 -97.45591735839844
180 -96.73572540283203
190 -96.95585632324219
200 -97.51351928710938
210 -96.92330932617188
220 -97.03160095214844
230 -96.88632202148438
240 -96.9697036743164
250 -97.35342407226562
260 -97.07598876953125
270 -97.24360656738281
280 -97.23467254638672
290 -97.02444458007812
300 -97.00311279296875
310 -97.07694244384766
320 -97.33139038085938
330 -97.15113830566406
340 -97.2895736694336
350 -97.41972351074219
360 -96.95799255371094
370 -97.36982727050781
380 -97.00273132324219
390 -97.10067749023438
400 -97.13653564453125
410 -96.87239074707031
420 -97.24083709716797
430 -97.04019165039062
440 -96.68864440917969
450 -97.19795989990234
460 -97.18959045410156
470 -97.09814453125
480 -97.11341857910156
490 -97.20771789550781
500 -97.39350128173828
510 -97.25328063964844
520 -97.20199584960938
530 -96.95065307617188
540 -97.37591552734375
550 -96.98526763916016
560 -97.0145263671875
570 -96.97329711914062
580 -97.04313659667969
590 -97.38460540771484
600 -97.31581115722656
610 -97.10185241699219
620 -97.22990417480469
630 -97.1851577758789
640 -97.15637969970703
650 -97.13624572753906
660 -97.0641860961914
670 -97.17774200439453
680 -97.31779479980469
690 -97.42807006835938
700 -97.18154907226562
710 -97.57279968261719
720 -96.99563598632812
730 -97.15852355957031
740 -96.85628509521484
750 -96.8902587890625
760 -97.11228942871094
770 -97.214111328125
780 -96.99479675292969
790 -97.30390930175781
800 -96.98690795898438
810 -97.12834167480469
820 -97.51512145996094
830 -97.41466522216797
840 -96.89874267578125
850 -96.84567260742188
860 -97.2318344116211
870 -97.24137115478516
880 -96.74853515625
890 -97.09489440917969
900 -97.13866424560547
910 -96.79051208496094
920 -97.06621551513672
930 -97.14911651611328
940 -97.26902770996094
950 -97.0196533203125
960 -96.95348358154297
970 -97.138916015625
980 -97.60130310058594
990 -97.25077056884766
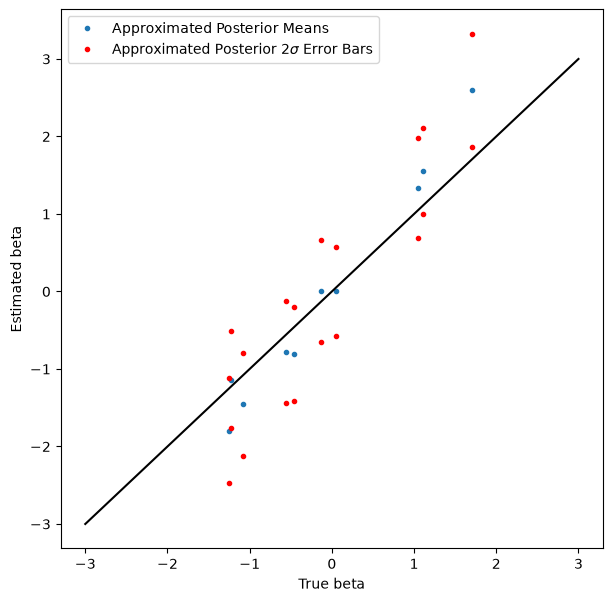
Display the results#
Coverage isn’t quite as good as we might like, but it’s not bad, and nobody said variational inference was exact.
plt.figure(figsize=(7, 7))
plt.plot(true_beta, beta_loc, '.', label='Approximated Posterior Means')
plt.plot(true_beta, beta_loc + 2*jnp.exp(beta_log_scale), 'r.', label=r'Approximated Posterior $2\sigma$ Error Bars')
plt.plot(true_beta, beta_loc - 2*jnp.exp(beta_log_scale), 'r.')
plot_scale = 3
plt.plot([-plot_scale, plot_scale], [-plot_scale, plot_scale], 'k')
plt.xlabel('True beta')
plt.ylabel('Estimated beta')
plt.legend(loc='best')
<matplotlib.legend.Legend at 0x7916f87a99a0>